In the 1960s, implementing a new operating system was considered a herculean effort, akin to the moon landing. Greer explains how just two engineers – Dennis Richie and Ken Thompson – accomplished such a feat while building Unix. Somehow, they managed to outpace the development of a large team of their contemporaries building Multics.
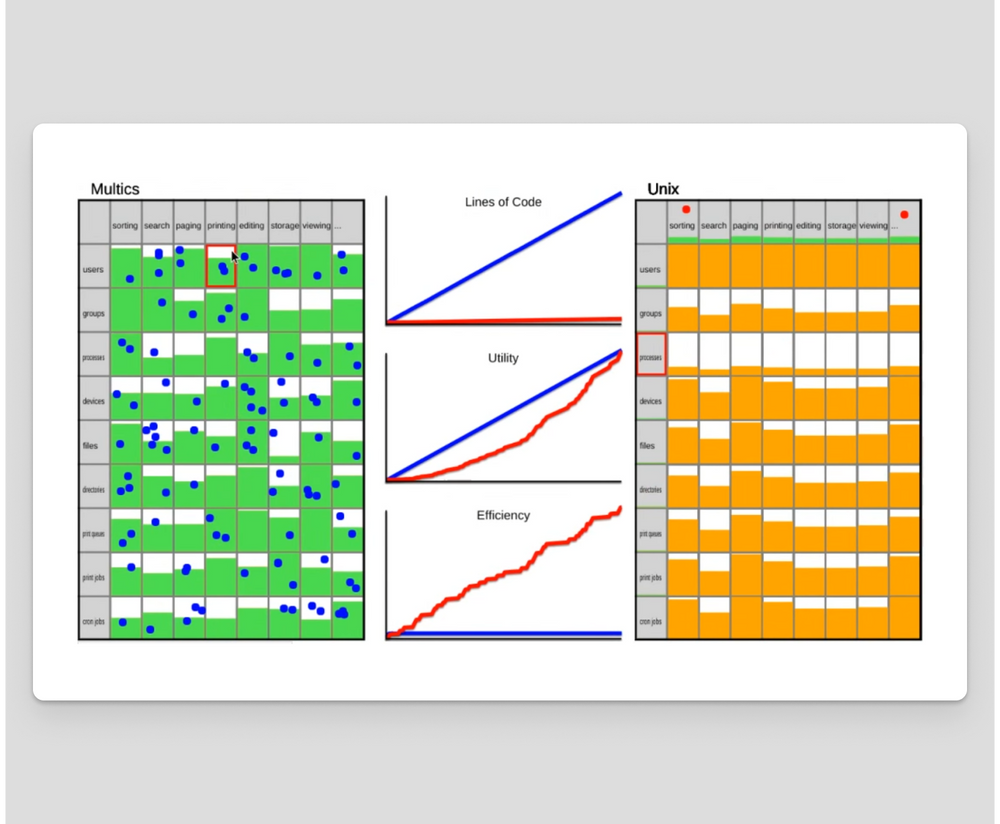
Greer’s argument is summarized by the following image. It shows a simulation of Ritchie and Thompson implementing Unix – represented by the two red dots on the right – as compared to the many blue dots on the left implementing Multics. The rows represent types of data and the columns represent features. The cells represent implementation progress. Unix’s approach to filesystems and pipes meant that they were able to “code the perimeter.” Richie and Thompson were therefore able to fill the area in O(N+M) effort instead of O(N*M).
Unix Philosophy is best summarized by Doug McIlroy:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
Often, this philosophy is further shortened to just the first sentence. The importance of the second and third sentences is oft-ignored. This shortening is no longer a valid summary! It’s not enough to write programs that do one thing well. You must also write programs that work together, utilizing universal interfaces.
“Programs should do one thing” is often invoked to justify favoring micro-services over monoliths. However, in the absence of collaboration over universal interfaces, you’re likely to find yourself coding the area instead of the perimeter. You wanted linear complexity, but all you got was rectangular complexity with an extra helping of distributed systems complexity.
Cloud computing is still at the Multics stage of evolution. We can do better. To do so, let’s analyze microservice development using Greer’s framework. Consider all the functionality expected of a modern, production-caliber web service. The list is massive, but to name a few: authentication, authorization, metrics, monitoring, alerting, provisioning, deployment, testing, logging, and tracing! And these requirements are fractal. If you zoom in, you’ll find each area is rich enough to have more than a couple of venture-funded startups attempting to address just that one area. Even if you use this functionality-as-a-service from one of these vendors, you still need to do the integration work.
If you’re building a monolith, your implementation matrix looks like this:
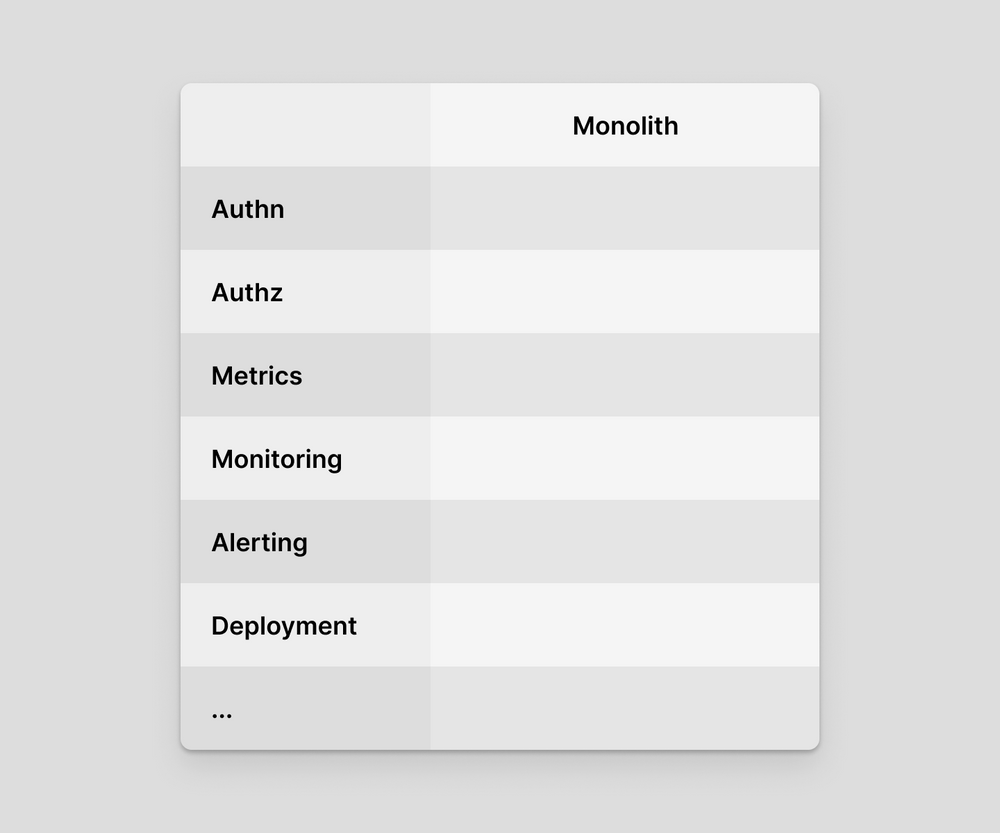
Here, functionality is rows and services are columns. Once you add additional services, the matrix looks like this:

If you’re lucky enough to have a platform team at your company, they’ve got their work cut out for them! Hopefully, they are not running around the area of the matrix like the many blue dots working on Multics, individually configuring functionality for each service. If you’re not so lucky to have an army of blue dots, you’re doomed unless you either (A) keep the number of services small or (B) code the perimeter!
This is where the second sentence of the Unix philosophy comes in: write programs to work together. For example, instead of configuring metrics once for each service, you might write a single reusable library (Unix philosophy point #1) that can be embedded into each service to act as the glue between that service and the common metrics service (point #2). Designing and implementing these glue libraries is not easy, but it is generally straightforward, and it’s linear work, not square.
OK, so let’s say you follow this approach. Twitter did precisely this with their Finagle RPC system. Functionality like request metrics, traffic splitting, retries, and more was coded once and then shared across every service at Twitter. Well, that is, every service at Twitter that runs on the JVM.
See, the brilliance of Unix didn’t stop at functional orthogonality, they also used C: A high-level programming language, as compared to machine-specific assembly code. Once Unix started getting ported to new hardware architectures, the two-dimensional implementation matrix becomes three-dimensional.
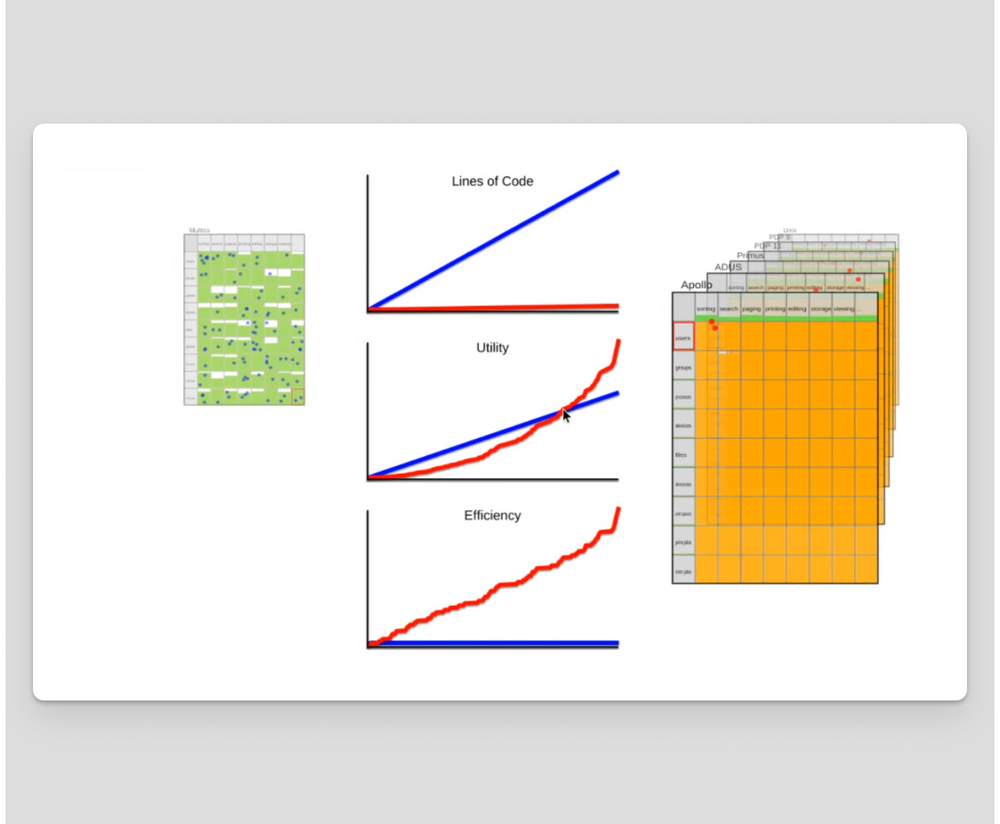
Now point number three of the Unix Philosophy comes into play: Use universal interfaces. The C abstract machine was close enough to a universal interface that the developers of Unix were still coding the perimeter, instead of the volume!
Turning our attention back to microservices, let’s further examine the Finagle RPC framework example. As Twitter’s data science and machine learning efforts grew, so too has their usage of Python. Polyglot programming is inevitable. However, Finagle is a JVM solution. It’s insufficiently universal to be applied to Python programs. If you want to get this functionality, you’re now coding the area of a 2D slice in the 3D space of services, functionality, and programming languages.
Cloud computing can escape the Multics stage of evolution. Sticking with the Finagle and the RPC example, we are beginning to see the adoption of service meshes. While still nascent, service meshes hold promise. They do one thing well: enhance network traffic with important operational functionality. Service meshes work together with other programs: by running as sidecars, embeddable with each service. And they utilize universal interfaces: TCP, HTTP, etc. As a result, a service mesh is coded once and immediately applicable to every service in every language.
Zooming out of the fractal complexity of RPC, we as a community need to find Unix-style solutions to a wide range of additional service-oriented architecture concerns. Our journey towards coding the perimeter is only just beginning. We can imagine a future in which each service, coded in any language, created at every company, comes into existence ready-to-go for a “production-caliber” deployment. This future is possible only by coding the perimeter, which requires embracing the Unix philosophy fully: all three sentences of it.
]]>This was originally posted to the the blog of my now defunct startup, Deref. I’ve republished it here for archival and my own future reference.

{kind=link}